
PIKES in a nutshell
PIKES is a tool for Knowledge Extraction that automatically extracts “things” of interest (e.g., events, persons, organizations), and facts about them, from a (potentially large) text corpus. We illustrate PIKES with the figure below, showing how PIKES processes a simple text document consisting of two sentences: “G.W. Bush and Bono are very strong supporters of the fight of HIV in Africa. Their March 2002 meeting resulted in a 5 billion dollar aid.”.
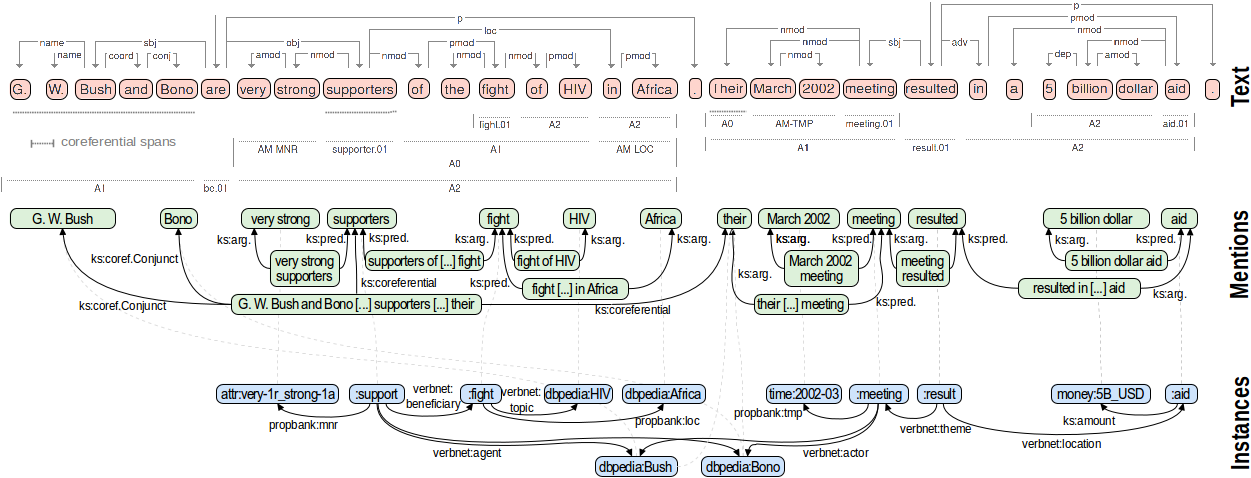
Starting from an English text resources (shown in red in the figure), PIKES applies a number of Natural Language Processing (NLP) tools to annotate it, ranging from ‘shallow’ NLP tasks such as tokenization and part-of-speech tagging to ‘deep’ NLP tasks such as dependency parsing (shown above the text) and semantic role labelling (shown below the text). In particular, the use of semantic role labelling allows PIKES to extract frames, i.e., prototypical situations consisting of predicate and role fillers (e.g., support.01 predicate with beneficiary role A1 ‘fight of HIV’ and manner AM-MNR ‘very strong’ in the figure).
NLP annotations are then translated to a graph of mentions (shown in green in the figure), which are spans of text denoting something of interest (e.g., the person ‘G. W. Bush’, the attribute ‘very strong’, the predicate ‘resulted’, …), enriched with attributes and relations precisely characterizing what they represent. Mentions aim at representing, in a structured form, all the information needed to extract the knowledge conveyed by the text, so that access to the text is not needed anymore.
Mentions from multiple sentences are finally processed to derive Instances (shown in blue in the figure), i.e., persons, locations, events and other entities of the domain of discourse abstracting from their textual realization, and to extract <subject, predicate, object> facts about them. PIKES accomplishes this step using a rule-based strategy that allows to interpret collected information handling relevant linguistic phenomena such as argument nominalizations, frame-frame relations and group entities.
The source text with its metadata (red part in the figure), the mentions extracted from it (green part) and the instances generated by applying rules (blue part) represent the three layers of PIKES representation model. This model is fully expressed in RDF according to Semantic Web best practices and, by exploiting the links between layers, allows to relate each triple produced at the Instances layer to the part (or parts) of text and the intermediate NLP output from where it was derived.
Additional details on how PIKES work are provided by the following pages: